
Architecture
The Arroyo system architecture is composed of several services, as can be seen in the following diagram:
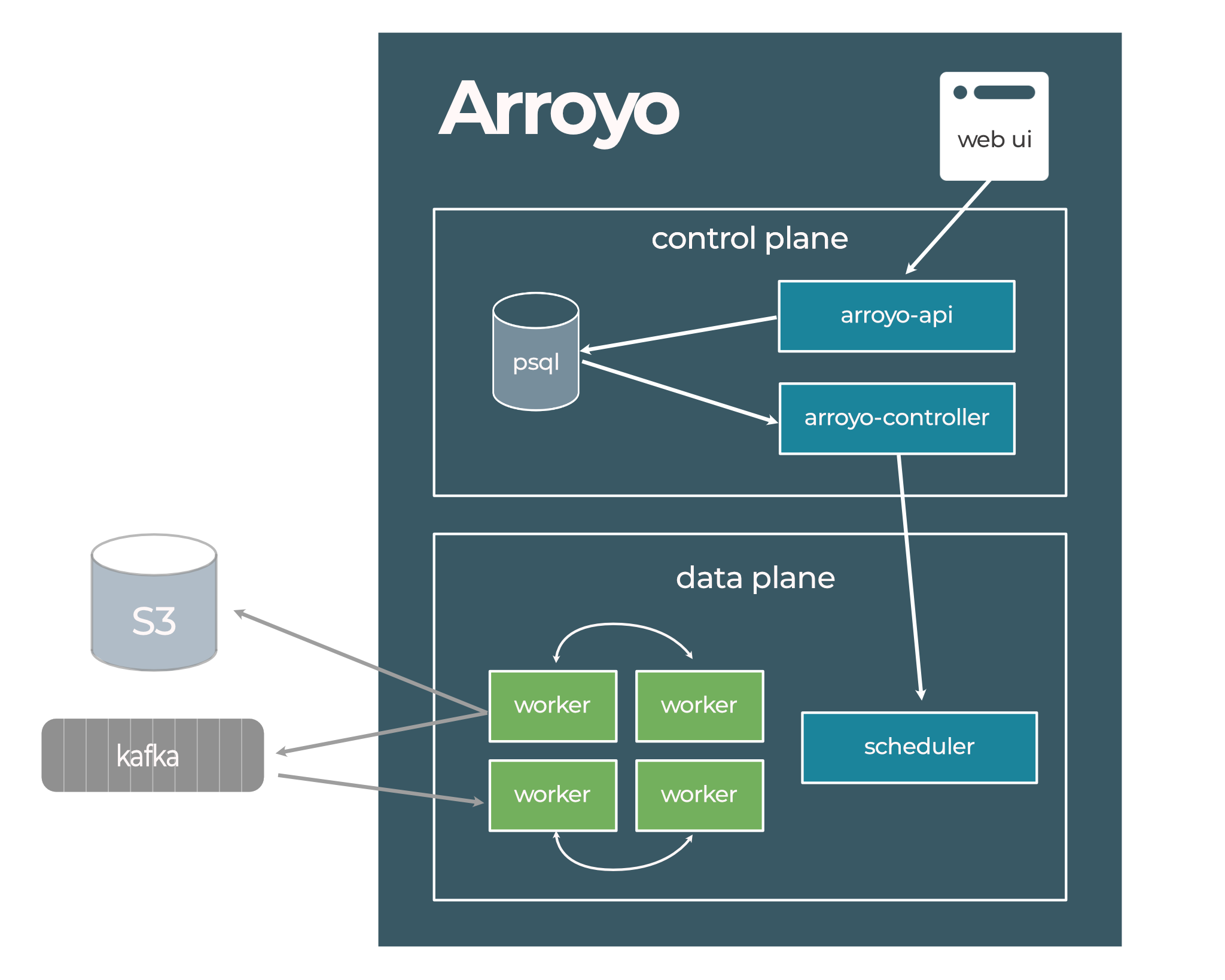
These services can be run in a single process for a simple deployment, or separately for a fully scaleable,
fault-tolerant system. All components of the system are compiled into a single binary arroyo
which provides sub-commands to run specific services or an entire Arroyo cluster.
This document will cover the subsystems that make up an Arroyo cluster.
Web UI
Section titled “Web UI”The Web UI is a web app that interacts with the system via the REST API. It allows users to configure the system, create pipelines, and monitor their statuses.
Arroyo API
Section titled “Arroyo API”The API server backs the Web UI and handles all configuration operations and pipeline management via the REST API.
API operations, like creating a pipeline or updating its state, operate solely by updating the configuration in the backing database. This is asynchronously applied to the actual state of the environment by the controller. The API itself is stateless and does not communicate with the rest of the system except via the database.
Arroyo Controller
Section titled “Arroyo Controller”The controller runs a control loop that continuously reconciles the desired state of the system (as defined in the database) with the actual state of the system, as determined by monitoring the environment. This is similar to a Kubernetes controller, (see here for an overview of this pattern).
There is a single controller instance that runs in the system, and high-availability is not yet supported in the open source release. If the controller instance fails, the workers will eventually stop and wait for the controller to come back online.
The controller manages a state machine for each job, which is documented here and is also responsible for initiating checkpoints on the workers. Communication between the controller and workers is done via the gRPC API defined in rpc.proto.
Schedulers
Section titled “Schedulers”Arroyo supports multiple schedulers, which are responsible for running the workers that make up the dataflow engine.
The scheduler can be set by setting the controller.scheduler config key.
Process Scheduler
Section titled “Process Scheduler”The process scheduler is the default scheduler. It spawns workers locally as independent processes.
Node Scheduler
Section titled “Node Scheduler”Arroyo comes with a lightweight scheduler and node runtime for running distributed workers. In this mode, you must start
some number of arroyo node processes (for example, in an autoscaling group) and configure them with the controller’s
address. The controller will then schedule workers on these nodes.
Kubernetes Scheduler
Section titled “Kubernetes Scheduler”Arroyo can be deployed to Kubernetes and configured to schedule workers on the cluster. See more details here.
Embedded Scheduler
Section titled “Embedded Scheduler”The embedded scheduler runs pipelines within the same process as the controller. This is most useful for development on Arroyo itself and is not recommended for production use.
Arroyo Worker
Section titled “Arroyo Worker”Workers run the actual processing logic, making up the dataplane. Workers run a binary that is produced by linking Rust code generated from the SQL query with the arroyo-worker library. Workers within the same pipeline are connected via TCP connections over which dataflow occurs. Each worker is configured with a number of slots, which controls how many subtasks it may run. By default, each slot runs a parallel slice of the entire DAG, which generally does a good job of balancing the load across workers.
The controller is responsible for scheduling the necessary number of workers to run a pipeline, initiating checkpoints, monitoring their health, and recovering from failures.
Config Database
Section titled “Config Database”The Arroyo control plane relies on a configuration database to store the registered tables and pipelines and to power the API and Web UI. Two databases are supported, with different scalability and reliability tradeoffs:
- Postgres is the recommended choice for high-scale and distributed clusters
- Sqlite is recommend when running locally and for pipeline clusters
Object stores
Section titled “Object stores”Arroyo relies on remote storage to store checkpoints so that pipelines can be recovered in case of failure or if they need to be rescaled or rescheduled. Local directories and remote object stores are supported; the former typically just for development and testing, while production use cases will use the latter. S3 (Amazon), GCS (Google Cloud), and ABS (Azure) are supported, as are alternative S3-compatible stores like Minio, Cloudflare R2, and Backblaze B2.
Job State Machine
Section titled “Job State Machine”Jobs are managed via a state machine that is implemented in the controller:

Jobs are initialized in the Created state when they are created via the API. Once the controller loads the job, it
will begin managing it, and is responsible for moving it to a terminal state (like Running, Stopped, Failed) within a
bounded amount of time.