
Formats
Arroyo supports a number of different data formats for connections, which control how data is serialized and deserialized. For some connectors, the format is fixed, while for others it can be configured.
The format is specified using the format option in SQL.
JSON is a common format for data interchange. Arroyo supports two flavors of JSON:
jsondebezium_json— JSON data in the format produced by Debezium for reading and writing from relational databases like Postgres
The following options are supported for both formats:
| Option | Description | Default |
|---|---|---|
format | The format of the data. Must be one of json or debezium_json. | json |
json.confluent_schema_registry | Set to true if data was produced by (or will be consumed via) a Confluent Schema Registry connected source | false |
json.include_schema | Set to true to include the schema in the output, allowing it to be used with Kafka Connect connectors that require a schema | false |
json.unstructured | Set to true to treat the data as unstructured JSON, which will be parsed as a single column of type TEXT | false |
json.timestamp_format | The format of timestamps in the data. May be one of rfc3339 or unix_millis | rfc3339 |
json.decimal_encoding | Controls how decimals are encoded into JSON. May be one of number, string, or bytes, which encodes as a two’s-complement, big-endian unscaled integer binary array, as base64 | number |
Json data can be either structured or unstructured. Structured data is parsed into columns according to the schema. Schemas can be specified via the fields in a SQL CREATE TABLE statement (as described in the DDL docs) or imported via a json-schema definition.
Note that json-schema is a very flexible format, and not all of its features can
be cleanly mapped to a SQL table. As a fallback, any fields that cannot be
directly supported by Arroyo will be rendered as a single column of type TEXT
with JSON-serialized data in it.
Unstructured data is treated as a single column named value with type TEXT, which can be operated on using
SQL json functions or UDFs.
Avro is a binary data format that is commonly used for data applications. Avro is a schema-based format, and requires readers and writers to have access to the schema in order to read and write data.
Avro is well-supported by the Kafka ecosystem where the Confluent Schema Registry, is a popular choice for storing and serving Avro schemas. Arroyo is able to read and write Avro schemas from the Schema Registry.
The following options are supported:
| Option | Description | Default |
|---|---|---|
format | The format of the data. Must be avro | avro |
avro.confluent_schema_registry | Set to true if data was produced by (or will be consumed via) a Confluent Schema Registry connected source | false |
avro.raw_datums | Set to true to serialize and deserialize as raw Avro datums instead of complete Avro records | false |
avro.into_unstructured_json | Convert the avro record to JSON | false |
Avro data can be serialized/deserialized in two ways:
- As a raw Avro datum, which is just the data itself
- As a complete Avro document, which includes the schema and metadata
In the former mode, applications reading from the data will need to have access to the exact schema used to write the data. This is the mode used for Confluent Schema Registry, as that provides a mechanism to distribute the schema to readers.
In the latter mode, the schema will be embedded in every record, allowing any application to read it without additional context. However, this is fairly inefficient as the schema will be repeated for every record.
The avro.into_unstructured_json option, if set, will cause the Avro data to be deserialized and re-serialized
to JSON, which can then be operated on using SQL json functions or UDFs.
This can be useful if the Avro schema for the data may change, and offers flexibility in how the data is
processed.
Schema Registry Integration
Section titled “Schema Registry Integration”For Kafka sources configured via the Web UI, Arroyo is able to automatically fetch the schema from the Schema Registry and use it to determine the schema for the table.
When using Avro with a Kafka sink, Arroyo will automatically register the schema with the Schema Registry so
long as the avro.confluent_schema_registry option is set to true. This allows the schema to be used by
other applications that read from the same topic.
Protobuf
Section titled “Protobuf”Protocol Buffers is a binary data format developed by Google that is commonly used for data interchange. Arroyo supports reading Protobuf data provided that the schema is available, along with support for fetching schemas from Confluent Schema Registry.
Sources with Protobuf schemas must currently be created via the Web UI or API, and are not yet supported in SQL.
The Protobuf schema definition looks like this:
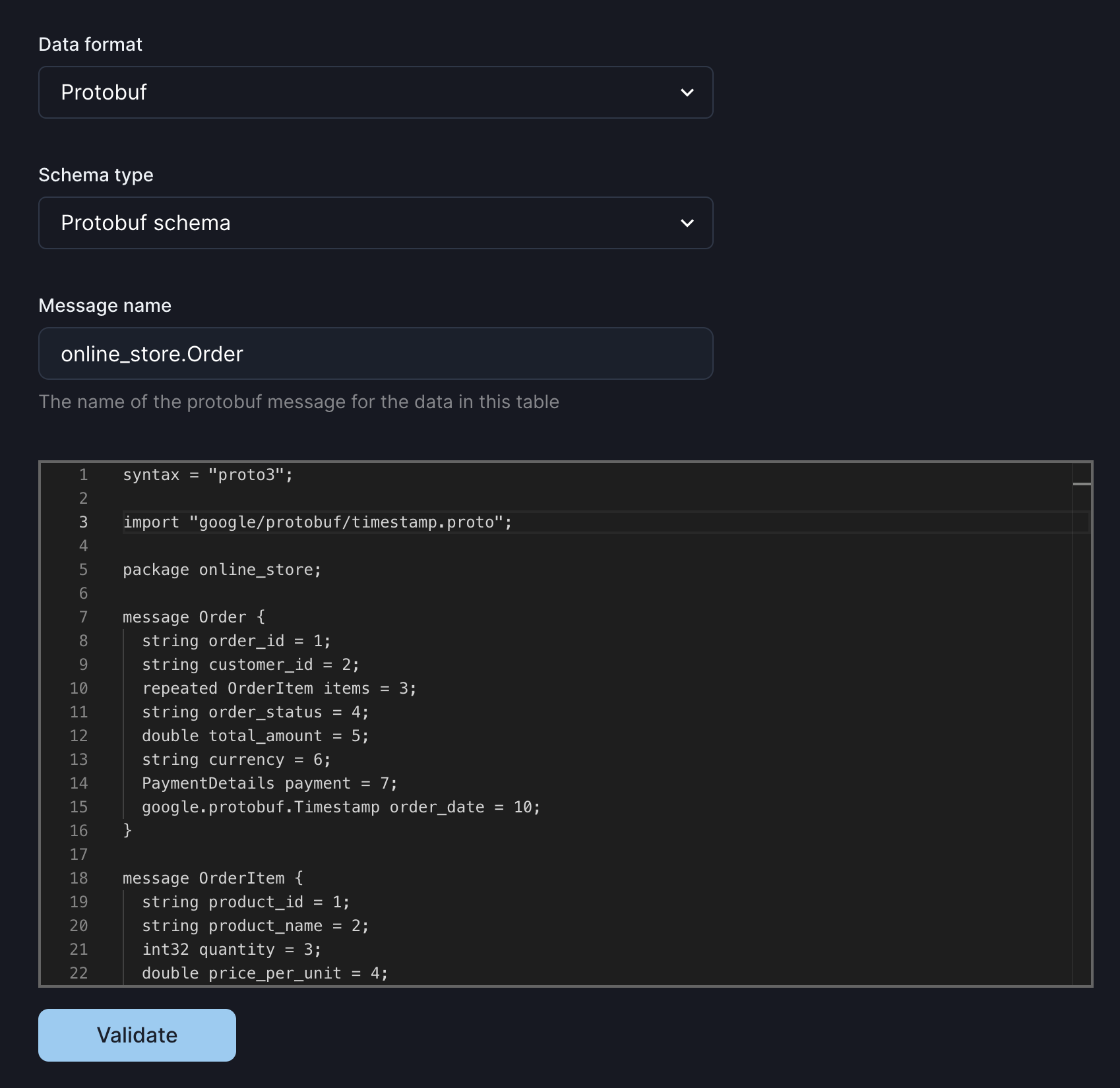
When creating a Protobuf source, you must provide the schema as a Protobuf definition. The schema may include multiple messages, enums, and other definitions, and may include imports of well-known Protobuf types. You must also provide the fully-qualified name of the message that will be used as the table schema.
To support multiple files and imports, you may use the create connection table API to create a Protobuf source.
For Kafka sources, Arroyo can automatically fetch the schema from the Confluent Schema Registry
if the Schema type is set to Schema registry.
Raw string
Section titled “Raw string”To ingest or emit arbitrary string data (encoded as UTF-8), you can use the
raw_string format. Raw string tables have a single column named value with
type TEXT, for example:
CREATE TABLE logs ( value TEXT) with ( format = 'raw_string', ...);Raw string data can be operated on using SQL string functions or UDFs.
Raw string is supported for both deserialization (from sources) and serialization (to sinks). As a serialization format, it can be useful for generating data in formats that Arroyo does not support natively, for example via UDFs:
/*[dependencies]serde_json = "1.0"*/
fn my_to_json(f: f64) -> String { let v = serde_json::json!({ "my_complex": { "nested_format": f } });
serde_json::to_string(&v).unwrap()}Similarly, for sources it can be used with a UDF to parse unsupported textual formats, as can be seen in the logfmt parsing tutorial.
Raw bytes
Section titled “Raw bytes”The raw bytes format allows users to ingest and emit arbitrary binary data. Together with a UDFs, this allows you to implement binary formats that are internal or otherwise not supported natively by Arroyo.
Raw bytes tables have a single column named value with type BYTEA:
CREATE TABLE events ( value BYTEA) with ( format = 'raw_bytes', ...);UDFs that operate on raw_bytes will take in an argument of type &[u8], for example:
#[udf]fn parse_string(data: &[u8]) -> Option<String> { Some(String::from_utf8(data.to_owned()).ok()?)}Parquet
Section titled “Parquet”Parquet is a columnar data format that is commonly used for storing data in data lakes. Arroyo supports writing Parquet via the FileSystem sink. Refer for the FileSystem sink docs for details.