
Overview
Arroyo interacts with other data systems via connectors, which can implement sources and sinks for reading and writing data respectively. The list of connectors is constantly expanding. If you’d like to connect Arroyo with a system that’s not currently supported, please get in touch with the team on Discord or via GitHub issues.
Supported Connectors
Section titled “Supported Connectors”| Name | Source | Sink | Lookup |
|---|---|---|---|
| Blackhole | No | Yes | No |
| Confluent Cloud | Yes | Yes | No |
| Filesystem | Yes | Yes | No |
| Fluvio | Yes | Yes | No |
| Impulse | Yes | No | No |
| Iceberg | No | Yes | No |
| Kafka | Yes | Yes | No |
| Kinesis | Yes | Yes | No |
| MySQL | Yes | Yes | No |
| MQTT | Yes | Yes | No |
| NATS | Yes | Yes | No |
| Nexmark | Yes | No | No |
| Polling HTTP | Yes | No | No |
| Postgres | Yes | Yes | No |
| RabbitMQ | Yes | No | No |
| Redis | No | Yes | Yes |
| Redpanda | Yes | Yes | No |
| Server-Sent Events | Yes | No | No |
| Webhook | No | Yes | No |
| WebSocket | Yes | No | No |
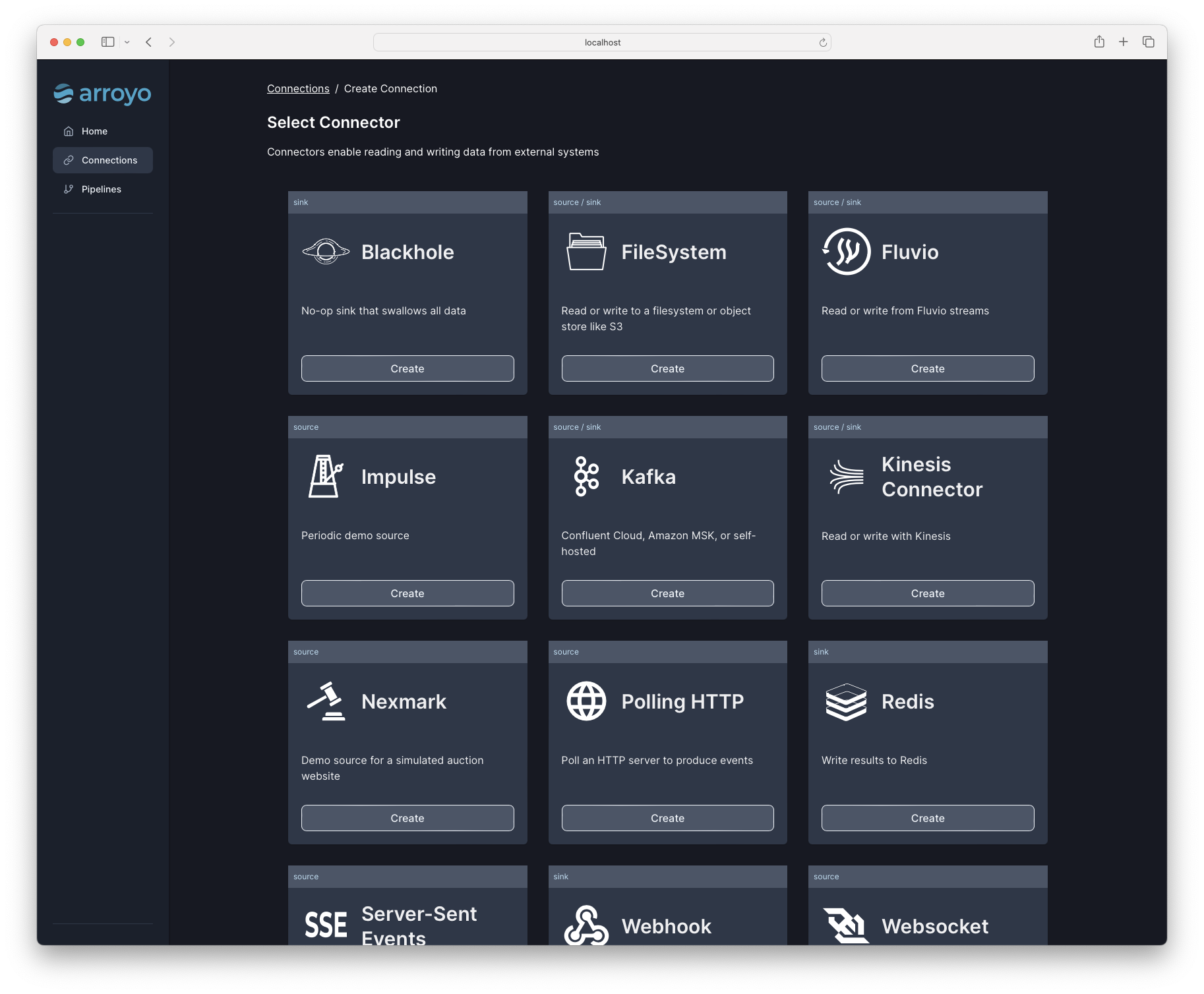
Using connectors
Section titled “Using connectors”Arroyo SQL supports a special kind of table called a connection table which is used to interact with external systems as sources or sinks.
Connection tables come in two forms. Saved connections are created in the Web UI or via the API and can be easily reused across queries. Existing saved connections can be viewed via the Connections tab of the Web UI, and their schemas can be seen in the catalogue view in the SQL editor.
Connection tables can also be created via CREATE TABLE statements in SQL, as described
in the DDL docs.
A particular connection table is either a source (meaning it reads data from an external system) or a sink (meaning it writes data). Some connectors support only one of these, while others support both.
See the individual connector docs for details on on their capabilities and how to configure them in Arroyo.
Event time and watermarks
Section titled “Event time and watermarks”Event time and watermarks are core to Arroyo’s dataflow semantics. These allow users to specify (1) a field of the data that represents the actual, real-world time an event occurred, and (2) how we should generate watermarks based on that time.
For SQL-created tables, event time and watermarks are specified with the syntax
WATERMARK FOR fieldname [AS watermark_expr]where fieldname is a TIMESTAMP field on the table, and watermark_expr is a SQL expression
over the table’s fields that produces a timestamp which will generate the watermark. For example:
CREATE TABLE events ( ts TIMESTAMP NOT NULL, id INT, WATERMARK FOR ts AS timestamp - INTERVAL '5 seconds') WITH ( ...)This will produce a table with event time set to the ts field, and a watermark with a fixed
5-second delay (i.e., we’ll consider data late once it’s 5 seconds older than the most recently
received data).
Connection profiles
Section titled “Connection profiles”For some connectors, Arroyo supports connection profiles, which allow you to define common connection details once and use it across multiple connections. Currently the Kafka, Redis, Kinesis, and MQTT connectors support connection profiles. Connection profiles are created as part of defining a saved connection in the Web UI, where they can be reused.
In SQL, you can directly specify a connection profile via the connection_profile option in the WITH clause.
Alternately, SQL users can manually specify the various options via the WITH clause.
Connection formats
Section titled “Connection formats”Arroyo supports a number of different data formats for reading and writing data, including
JSON, Avro, Parquet, and raw strings. The format is configured via the format option
when creating a SQL table.
See the format docs for more details on how to configure each format.
Framing
Section titled “Framing”The framing configuration for a source determines how messages read from the source are split into records for processing. This is particularly useful for sources—like HTTP endpoints—that do not have their own framing protocol.
By default, the framing is none, which means that the source will emit a
single record for each message it reads.
Framing is configured via the framing option when creating a SQL table. Currently
only newline is supported, which splits the input on newlines.
You may also set framing.newline.max_length to a number of bytes to limit the
maximum length of a single record. Records that exceed this length will be truncated.
For example:
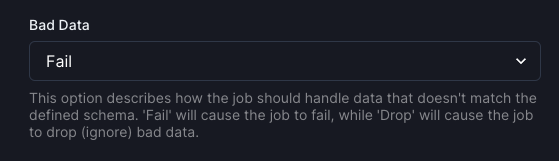
CREATE TABLE my_source ( value TEXT) WITH ( ... framing = 'newline', 'framing.newline.max_length' = '10000')Bad Data
Section titled “Bad Data”The bad_data option allows you to configure how Arroyo handles records that fail
to parse.
fail: fail the job (default)drop: drop the record and continue processing
You can configure it in the Web UI when creating a connection:
Or in SQL:
CREATE TABLE my_source ( value TEXT) WITH ( ... bad_data = 'drop')Connection schemas
Section titled “Connection schemas”Connections in Arroyo must have associated schemas to allow them to be used in SQL queries. Schemas describe how to interpret the data, mapping it into a table composed of Arroyo SQL types.
Schemas can be defined when creating the source in the Web UI or API, which allows them to be reused across queries. Arroyo supports several methods of schema definition, some of which are also associated with a particular data format:
Json and Avro Schemas for Kafka topics can also be read automatically from Confluent Schema Registry.
Source metadata
Section titled “Source metadata”Fields in a source table are typically filled in from the underlying data in the source;
for example from the fields of a JSON message in a Kafka topic. However it’s also possible
to inject metadata fields into the table, using the METADATA FROM key syntax:
create table users ( id TEXT, name TEXT, offset BIGINT METADATA FROM 'offset_id', partition INT METADATA FROM 'partition') with ( connector = 'kafka', ...);Each connector will expose different metadata fields, which can be accessed by
passing their name to the metadata function; in this example we use
the offset_id and partition fields exposed by the Kafka connector.
See the individual connector docs for supported metadata fields.
Source idleness
Section titled “Source idleness”Partitioned sources (like Kafka or Kinesis) may experience periods when some partitions are active but others are idle due to the way that they are keyed. This can cause issues in Arroyo due to how watermarks are calculated: as the minimum of the watermarks of all partitions.
If some partitions are idle, the watermark will not advance, and queries that depend on it will not make progress. To address this, sources support a concept of idleness, which allows them to mark partitions as idle after a period of inactivity. Idle partitions, meanwhile, are ignored for the purpose of calculating watermarks and so allow queries to advance.
Idleness is enabled by default for all sources with a period of 5 minutes. It can be
configured when creating a source in SQL by setting the idle_micros options, or disabled
by setting it to -1.
A special case of idleness occurs when there are more Arroyo source tasks than partitions (for example, a Kafka topic with 4 partitions read by 8 Arroyo tasks). This means that some tasks will never receive data, and so will never advance their watermarks. This can occur as well for non-partitioned sources like WebSocket, where only a single task is able to read data.
To address this, source tasks with no work assigned to them will mark themselves as idle immediately.
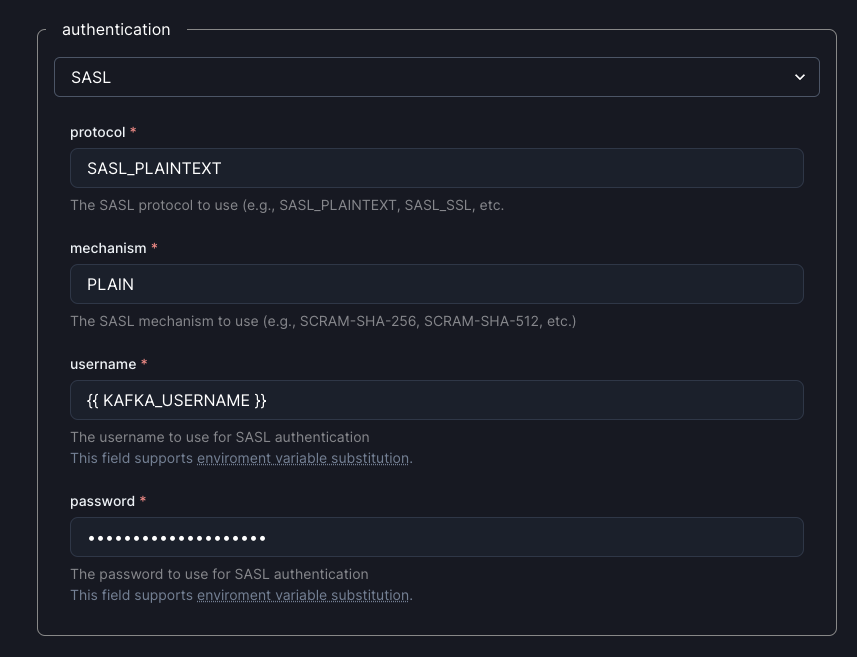
Environment variable substitution
Section titled “Environment variable substitution”Some fields in the connection configurations can use environment variables to substitute values at runtime. This is useful for secrets or other values that you don’t want to hard-code. Currently, environment variable substitution is supported for fields containing API keys, usernames, passwords, and HTTP headers.
You can use double curly braces ({{ }}) to indicate a substitution.
For example, in the Web UI:
Or directly in SQL like this:
CREATE TABLE data ( value TEXT) WITH ( connector = 'polling_http', endpoint = 'https://mywebserver.com/api/data', method = 'GET', headers = 'Authorization: bearer {{ MY_TOKEN }}', format = 'json');