
Redis
Arroyo includes two types of Redis connectors: a sink and a lookup connector, for lookup joins.
The Redis sink allows you to write data to a Redis instance or cluster. Redis is a great choice for use cases where you need low-latency access to the outputs of your Arroyo pipeline.
The Redis sink uses pipelining to achieve high throughput and is capable of writing millions of records per second to a single Redis instance.
Redis supports a variety of data structures. Currently, the Redis sink supports writing to the following data structures:
Each value in Redis is identified by a key. The configuration of the Redis sink allows you to construct the key in various ways, including a fixed prefix and a suffix constructed from the columns of the result.
The value for each record will be the serialized representation of the row, using the configured format.
Configuring the Connection
Section titled “Configuring the Connection”Redis sinks can be created in the Web UI or directly in SQL.
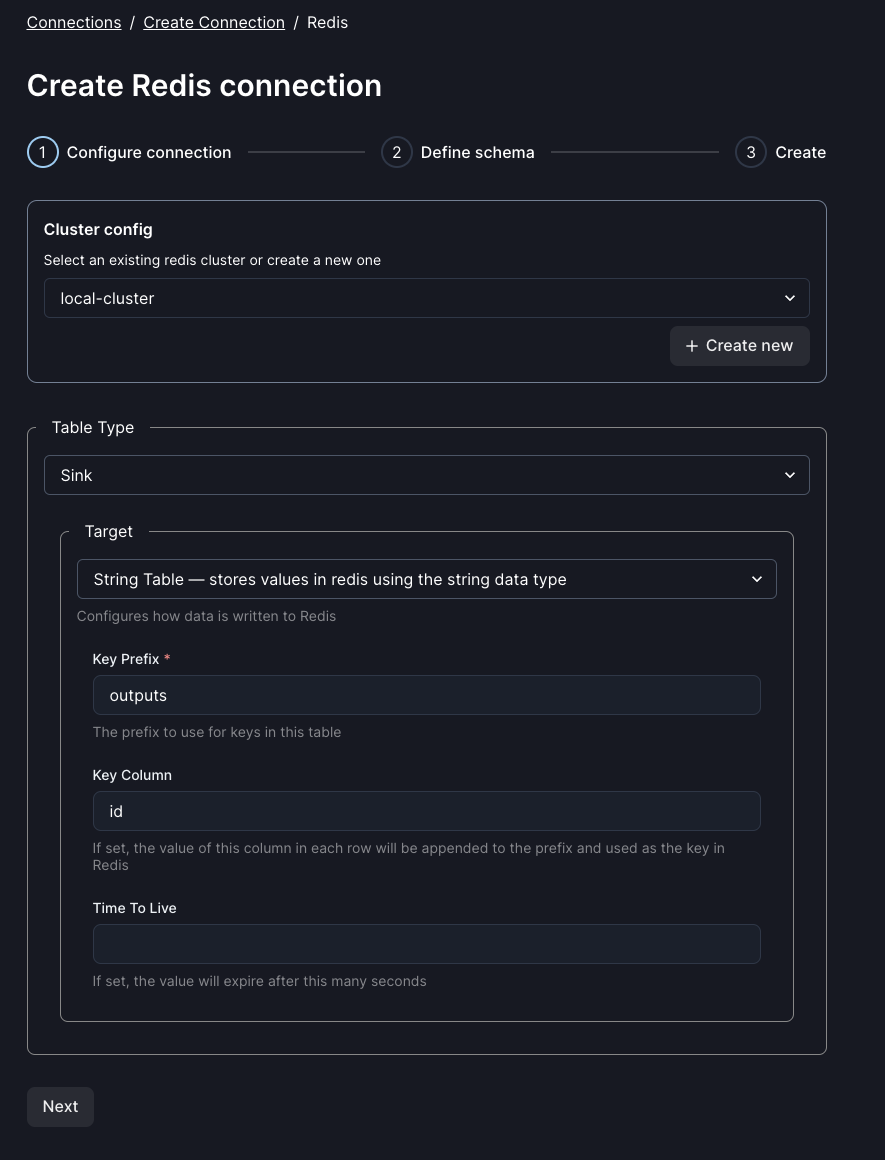
General configuration
Section titled “General configuration”| Field | Description | Required | Example |
|---|---|---|---|
| address | The address of a single, non-clustered Redis instance | No* | redis://localhost:6379 |
| cluster.addresses | A comma-separated list of addresses of Redis instances in a cluster | No* | redis://localhost:6379,redis://localhost:6380 |
| type | The type of table (currently only sink is supported) | Yes | sink |
| target | The data type to write to. Currently, string, hash, and list are supported | Yes | string |
| target.key_prefix | A prefix that will be prepended to all keys | Yes | outputs. |
| target.key_columns | A column whose value will be appended to the key for each record | No | id |
string target
Section titled “string target”| Field | Description | Required | Example |
|---|---|---|---|
| target.ttl_secs | The time-to-live for each key in seconds | No | 3600 |
list target
Section titled “list target”| Field | Description | Required | Example |
|---|---|---|---|
| target.max_length | The max length for this list; once the list exceeds this, the oldest elements will be dropped | No | 100 |
| target.operation | The operation to perform on the list; one of ‘append’ (default) or ‘prepend’ | No | append |
hash target
Section titled “hash target”| Field | Description | Required | Example |
|---|---|---|---|
| target.field_column | This column will be used as the field name in the hash | Yes | key |
Example
Section titled “Example”CREATE TABLE redis ( user_id TEXT NOT NULL, event_count BIGINT NOT NULL,) WITH ( connector = 'redis', type = 'sink', format = 'json', 'address' = 'redis://localhost:6379', target = 'string', 'target.key_prefix' = 'outputs.', 'target.key_column' = 'user_id');
INSERT INTO redisSELECT user_id, count(*)FROM eventsGROUP BY user_id, hop(interval '5 seconds', interval '1 hour');Given the above query, we can see the following output in Redis:
$ redis-cli127.0.0.1:6379> GET outputs.fred"{\"user_id\":\"fred\",\"event_count\":10}"Lookup
Section titled “Lookup”Redis can also be used as a source for lookup joins. When used in
a lookup join, queries are made via a Redis GET command, supporting key-value records.
Lookup tables must currently be created via SQL. A Redis lookup table looks like this:
CREATE TEMPORARY TABLE customers ( -- For Redis lookup tables, it's required that there be a single -- METADATA FROM 'key' marked as PRIMARY KEY, as Redis only supports -- efficient lookups by key customer_id TEXT METADATA FROM 'key' PRIMARY KEY, name TEXT, plan TEXT) with ( connector = 'redis', address = 'redis://localhost:6379', format = 'json', 'lookup.cache.max_bytes' = 1000000, 'lookup.cache.ttl' = interval '5 seconds');The address and format arguments are required.