
Fluvio
Arroyo provides sources and sinks for Fluvio for consistently reading and writing data from Fluvio topics. Fluvio is a distributed streaming platform built on top of Rust and Kubernetes. Fluvio has support for simple, stateless processing, but with Arroyo it can be extended to perform complex, stateful processing and analytics.
Configuring the Connection
Section titled “Configuring the Connection”Fluvio connections can be created via the Web UI or in SQL.
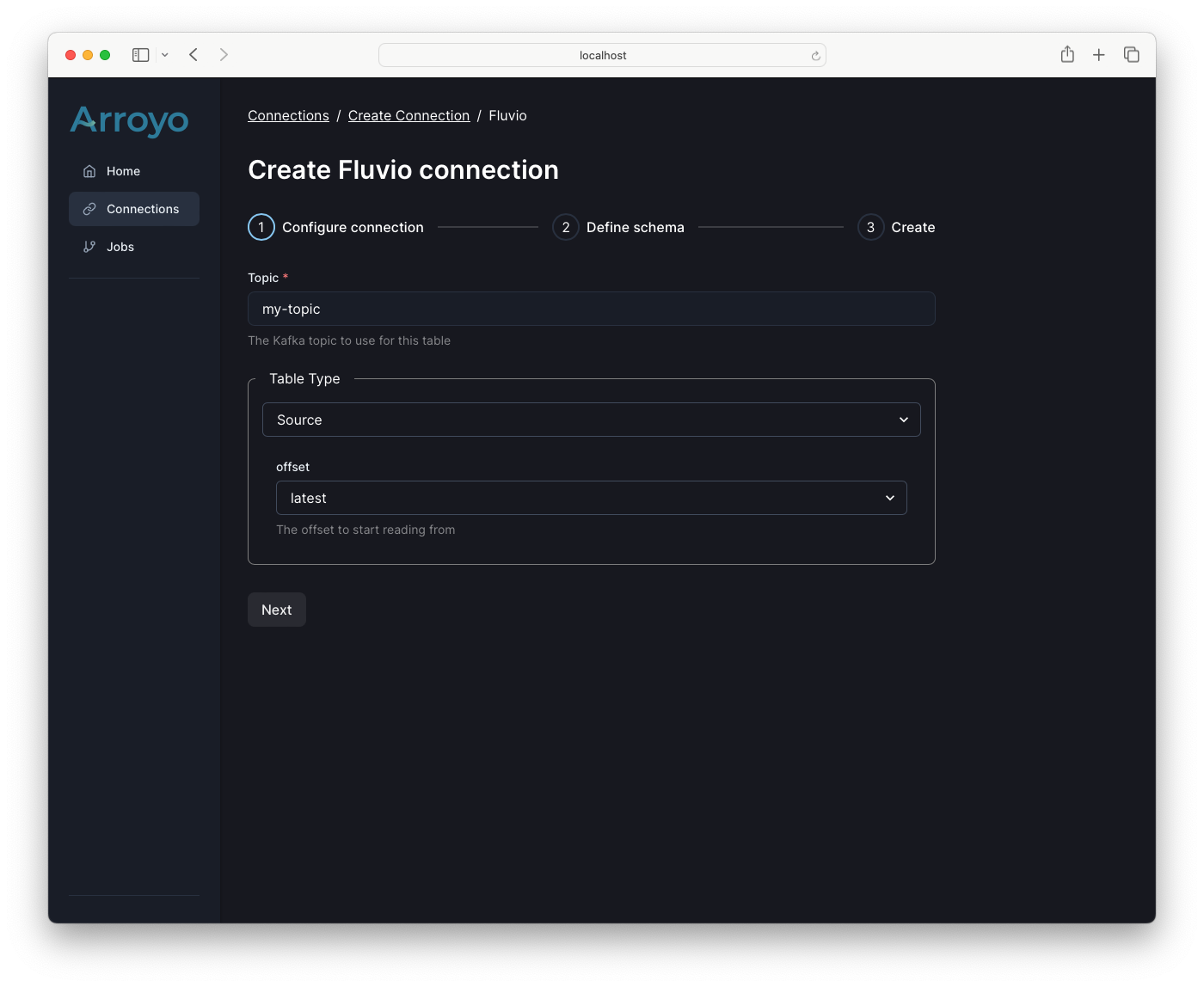
A Fluvio connection has several required and optional fields:
| Field | Description | Required | Example |
|---|---|---|---|
| endpoint | The endpoint of your Fluvio cluster; if not specified the default profile is used | No | my-cluster:9003 |
| topic | The name of the Fluvio topic to read from or write to | Yes | |
| type | The type of table (either ‘source’ or ‘sink’) | Yes | source |
| source.offset | The offset to start reading from (either ‘earliest’ or ‘latest’) | If source | earliest |
Fluvio Sources
Section titled “Fluvio Sources”Fluvio sources can be created via the Web UI, the API, or directly in SQL. A Fluvio source is defined by a topic name and a schema.
Schemas can be defined via json-schema or via SQL DDL statements.
Fluvio sources implement exactly-once semantics by storing the last-read offset in Arroyo’s state.
Fluvio Sinks
Section titled “Fluvio Sinks”Fluvio sinks can be created via the Web UI, the API, or directly in SQL. A Fluvio sink is defined by a topic name and schema. Currently, Fluvio sinks only support writing JSON data, with the structure determined by the schema of the data being written.
Fluvio DDL
Section titled “Fluvio DDL”Fluvio sources and sinks can be created directly in SQL. For example:
CREATE TABLE source ( value TEXT) WITH ( connector = 'fluvio', format = 'raw_string', topic = 'greetings', type = 'source');
CREATE TABLE sink ( msg TEXT) WITH ( connector = 'fluvio', format = 'json', topic = 'fluvio-sink', type = 'sink');