
Postgres
Arroyo supports Postgres as a source and sink, via Debezium. A native Postgres connector is planned for the future.
Debezium is a CDC (change data capture) tool that monitors the Postgres transaction log and publishes changes to Kafka. Arroyo can read these changes from Kafka and present them as streaming tables which can be queried like any other table.
Currently Debezium tables must be created via CREATE TABLE calls in SQL and must be configured
with format = 'debezium_json'. Otherwise, the options are the same as for other
Kafka sources.
Postgres Sources
Section titled “Postgres Sources”Setting up Debezium
Section titled “Setting up Debezium”To read from Postgres via Debezium, you will first need to set up Debezium to read from your Postgres changelogs and publish them to Kafka. See the Debezium Postgres docs for more details on how to set this up.
An example Debezium config could look like this:
{ "name": "arroyo-connector", "config": { "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.hostname": "localhost", "database.port": "5432", "database.user": "user", "database.password": "password", "database.dbname": "my_database", "tombstones.on.delete": "false", "table.include.list": "public.table_name", "topic.prefix": "debezium", "plugin.name": "pgoutput", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false" }}This will create a Kafka topic called debezium.public.table_name which will contain
the changes to the public.table_name table in Postgres.
To verify that this is working, you can use the kafka-console-consumer tool in your
Kafka installation to read from the topic:
kafka-console-consumer --bootstrap-server localhost:9092 --topic debezium.public.table_nameYou should see a stream of JSON objects representing the changes to the table that look like this:
{"before":null,"after":{"id":1,"name":"foo","age":42},"source":{"version":"2.3.2.Final","connector":"postgresql","name":"debezium","ts_ms":1691786140166,"snapshot":"false","db":"timescale","sequence":"[\"10642191632\",\"10642191688\"]","schema":"public","table":"table_name","txId":418604,"lsn":10642191688,"xmin":null},"op":"c","ts_ms":1691786140421,"transaction":null}{"before":null,"after":{"id":1,"name":"bar","age":42},"source":{"version":"2.3.2.Final","connector":"postgresql","name":"debezium","ts_ms":1691786140167,"snapshot":"false","db":"timescale","sequence":"[\"10642191968\",\"10642191968\"]","schema":"public","table":"table_name","txId":418605,"lsn":10642191968,"xmin":null},"op":"u","ts_ms":1691786140424,"transaction":null}{"before":{"id":1,"name":null,"age":null},"after":null,"source":{"version":"2.3.2.Final","connector":"postgresql","name":"debezium","ts_ms":1691786149069,"snapshot":"false","db":"timescale","sequence":"[\"10642192096\",\"10642192272\"]","schema":"public","table":"table_name","txId":418606,"lsn":10642192272,"xmin":null},"op":"d","ts_ms":1691786149093,"transaction":null}Creating a Debezium table in Arroyo
Section titled “Creating a Debezium table in Arroyo”Once you have a Debezium topic set up, you can create a table in Arroyo that will read
from that topic. This is a normal Kafka source table, but you must set the format to
debezium_json and the topic to the Debezium topic you created above.
CREATE TABLE debezium_table ( id int, name string, age int) WITH ( format = 'debezium_json', connector = 'kafka', type = 'source', bootstrap_servers = 'localhost:9092', topic = 'debezium.public.table_name')This will create a table called debezium_table that will read from the topic
debezium.public.table_name and will have the schema id int, name string, age int.
You can then query this table like any other table in Arroyo:
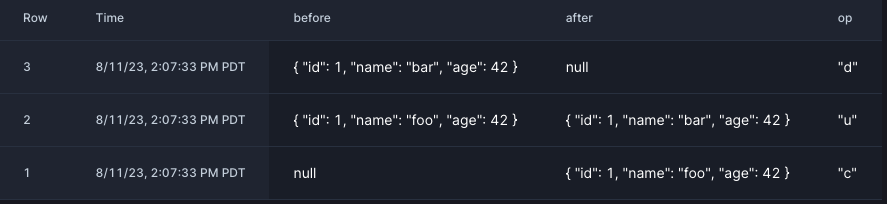
SELECT * FROM debezium_table;which should produce output like this:
Postgres Sinks
Section titled “Postgres Sinks”Setting up a Postgres sink
Section titled “Setting up a Postgres sink”Arroyo can write query results to Postgres via the Debezium connector for JDBC.
There are several steps to setting up a Postgres sink.
Step 1: Create topic
Section titled “Step 1: Create topic”Create a Kafka topic to write to. This can be done via the
kafka-topics tool in your Kafka installation:
./kafka-topics.sh --bootstrap-server localhost:9092 --create \ --topic my_sinkStep 2: Create table
Section titled “Step 2: Create table”Create the destination table in Postgres:
CREATE TABLE my_sink ( time TIMESTAMP, product TEXT, price FLOAT);Step 3: Configure Debezium
Section titled “Step 3: Configure Debezium”Configure the Debezium sink connector to write to the Postgres table:
{ "name": "jdbc-connector", "config": { "connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector", "consumer.override.auto.offset.reset": "latest", "tasks.max": "1", "connection.url": "jdbc:postgresql://localhost/database", "connection.username": "user", "connection.password": "password", "database.time_zone": "UTC", "topics": "my_sink", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter.schemas.enable": true, "value.converter": "org.apache.kafka.connect.json.JsonConverter" }}curl -XPOST localhost:8083/connectors -d@connector.json \ -H "Content-Type: application/json"Writing to a Postgres sink
Section titled “Writing to a Postgres sink”Now that we’ve set up Debezium, we can write to the sink table from Arroyo.
A Postgres Debezium sink table is a normal Kafka sink table, with some additional options set.
CREATE TABLE prices ( time TIMESTAMP, product_id TEXT, price FLOAT) WITH ( connector = 'kafka', bootstrap_servers = 'localhost:9092', topic = 'my_sink', type = 'sink', format = 'debezium_json', 'json.include_schema' = 'true');This can be inserted into via a query like
INSERT INTO pricesSELECT window.end_time, price, product_id FROM (SELECT avg(CAST(price as FLOAT)) as price, hop(interval '5' second, interval '1 minute') as window, product_idfrom tickersGROUP BY window, product_id);